
정보처리기사(3과목 데이터베이스 구축)
카테고리: IPE

3과목 데이터베이스 구축 필기 (요약)
34. 인덱스(Index)
- 데이터베이스 성능에 많은 영향을 주는 DBMS 의 구성 요소로 테이블과 클러스터에 연관되어 독립적인 저장 공간을 보유하며, 데이터베이스에 저장된 자료를 더욱 빠르게 조회하기 위하여 별도로 구성한 순서 데이터를 말한다
- 데이터베이스 대부분에서 테이블을 삭제하면 인덱스도 같이 삭제된다
35. 트리 순회, 연산식
- 전위 순회(Preorder) : [루트 -> 왼쪽 자식 -> 오른쪽 자식]순으로 순회
- 중위 순회(Inorder) : [왼쪽 자식 -> 루트 -> 오른쪽 자식]순으로 순회
- 후위 순회(Postorder) : [왼쪽 자식 -> 오른쪽 자식 -> 루트]순으로 순회
36. 해싱 함수의 종류
해싱 함수의 종류 : 제산 방법(Division Method), 중간 제곱 방법(Mid-Square Method), 중첩 방법(폴딩, Folding Method), 기수 변환 방법(Radix Conversion Method), 무작위 방법(Random Method), 계수 분석 방법(Digit Analysis Method)
37.데이터베이스 설계
개념적 설계
- 요구 분석 단계에서 나온 결과(명세)를 E-R(Entity-Relation-ship) 다이어그램과 같은 DBMS 에 독립적이고 고차원적인 표현 기법으로 기술하는 과정이다
- 요구 조건 분석 결과로 식별된 응용을 검토해서 이들을 구현 할 수 있는 트랜잭션을 고차원 명세로 기술하는 과정이다
논리적 설계
- 목표 DBMS 에 종속적인 논리적 스키마 작성
- 논리적 데이터 모델로 변환
- 트랜잭션 인터페이스 설계
- 스키마의 평가 및 정제
물리적 설계
- 목표 DBMS 에 종속적인 물리적 구조 설계
- 저장 레코드 양식 설계 및 레코드 집중의 분석/설계
- 파일 조직 방법과 저장 방법 그리고 파일 접근 방법 등을 선정
- 응답 시간 효율화를 위한 접근 경로 설계
- 트랜잭션 세부 설계
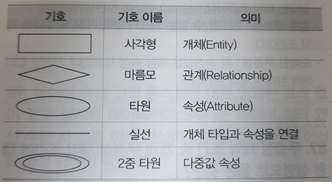
38. E-R 다이어그램
39. 릴레이션의 구성
관계형 데이터베이스 모델 구조
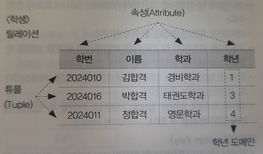
속성(Attribute)
- 테이블의 열(Column)에 해당하며 파일 구조의 항목(Item), 필드(Field)와 같은 의미이다
- 디그리(Degree) : 속성의 수(차수)
튜플(Tuple)
- 파일 구조의 각 행을 튜플이라고 한다. 레코드와 같은 의미이다
- 카디널리티(Cardinality) : 튜플(행)의 수(기수)
40. 키(Key)
기본키(Primary Key)
- 테이블의 각 레코드를 고유하게 실별하는 필드나 필드의 집합니다
- 테이블에 기본키 설정은 필수가 아니다
- 기본키를 설정하지 않고도 다른 테이블과의 관계를 설정할 수 있다
- 관계가 설정되어있는 테이블에서 기본키 설정을 해제하더라도 설정된 관계는 유지된다
- 데이터가 이미 입력된 필드도 기본키로 지정할 수 있으며 기본키 값은 변경될 수 있다
외래키(Foreign Key)
- 관계형 데이터 모델에서 한 릴레이션의 외래키는 참조되는 릴레이션의 기본키와 대응되어 릴레이션 간에 참조 관계를 표현하는 데 사용되는 중요한 도구이다
- 외래키를 포함하는 릴레이션이 참조하는 릴레이션이 되고, 대응되는 기본키를 포함하는 릴레이션이 참조 릴레이션이 된다
41. 무결성의 종류
- 개체 무결성 : 기본키의 값은 널(Null)값이나 중복값을 가질 수 없다는 제약 조건이다
- 참조 무결성 : 참조할 수 없는 외래키 값을 가질 수 없다는 제약 조건이다
- 도메인 무결성 : 각 속성값은 해당 속성 도메인에 지정된 값이어야 한다는 제약 조건이다
42. 이상현상(Anomaly)
- 릴레이션 조작 시 데이터들이 불필요하게 중복되어 예기치 않게 발생하는 곤란한 현상을 의미한다
- 종류 : 삽입 이상, 삭제 이상, 갱신 이상
43. 정규화(Normalization)
- 함수적 종속성 등의 잘못 설계된 관계형 스키마를 더 작은 속성의 세트로 쪼개어 바람직한 스키마로 만들어 가는 과정이다
- 데이터베이스의 논리적 설계 단계에서 수행한다
- 데이터 구조의 안정성을 최대화한다
- 중복을 배제하여 삽입, 삭제, 갱신 이상의 발생을 방지한다
- 데이터 삽입 시 릴레이션을 재구성할 필요성을 줄인다
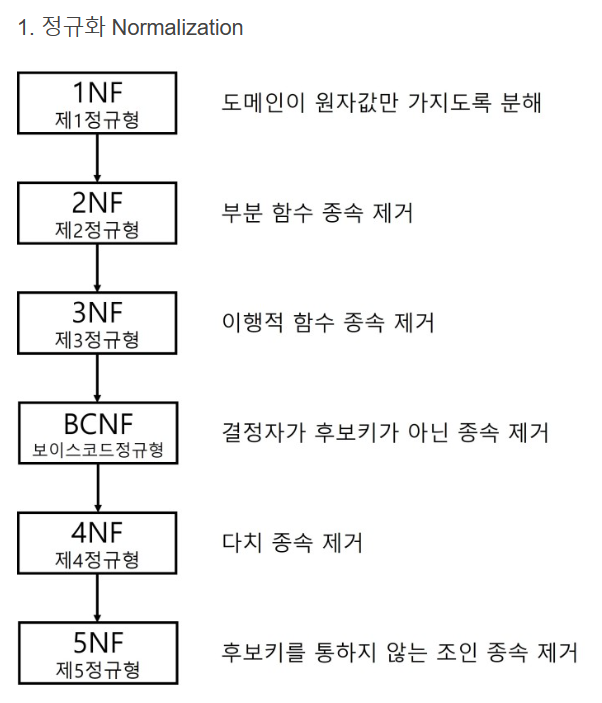
44. 병행 제어/로킹
병행 제어의 목적
- 데이터베이스 공유 최대화
- 데이터베이스 일관성 최대화
- 시스템 활용도 최대화
- 사용자에 대한 응답 시간 최소화
로킹(Locking)특징
- 로킹 단위가 커지면 로크의 수가 적어 관리가 쉬워지지만 병행성 수준은 낮아진다
- 로킹 단위가 작으면 로크의 수가 많아 관리가 어려워지지만, 병행성 수준은 높아진다
- 로킹의 대상이 되는 객체(파일, 테이블, 필드, 레코드)의 크기를 로킹 단위라고 한다
45. 분산 데이터베이스의 투명성
- 위치 투명성(Location Transparency) : 하드웨어와 소프트 웨어의 물리적 위치를 사용자가 알 필요가 없다
- 중복(복제) 투명성(Replication Transparency) : 사용자에게 통지할 필요 없이 시스템 안에 파일들과 자원들의 부가적인 복사를 자유롭게 할 수 있다
- 병행 투명성(Concurrency Transparency) : 다중 사용자들이 자원들을 자동으로 공유할 수 있다
- 장애 투명성(Faiure Transparency) : 사용자들은 어느 위치의 시스템에 장애가 발생했는지 알 필요가 없다
- 분산 데이터베이스의 구성 요소 : 분산 처리기, 분산 데이터베이스, 통신 네트워크, 분산 트랜잭션
- 분산 데이터베이스의 구조 : 전역, 분할(단편화), 할당, 지역 스키마
46. 관계 대수(Relational Algebra)
관계 대수
- 원하는 정보와 그 정보를 어떻게 유도하는가를 기술하는 절차적인 방법이다
- 주어진 릴레이션 조작을 위한 연산의 집합이다
- 질의에 대한 해를 구하기 위해 수행해야 할 연산의 순서를 명시한다
- 릴레이션 조작을 위한 연산의 집합으로 피연산자와 결과가 모두 릴레이션이다
- 일반 집합 연산과 순수 관계 연산으로 구분된다
순수 관계 연산자의 종류
| 종류 | 내용 |
|---|---|
| Select | 튜플 집합을 검색한다 |
| Project | 속성 집합을 검색한다 |
| Join | 두 릴레이션의 공통 속성을 연결한다 |
| Division | 두 릴레이션에서 특정 속성을 제외한 속성만 검색한다 |
47. SQL의 분류
- DDL의 종류 : CREATE, DROP, ALTER
- DML의 종류 : SELECT, INSERT, DELETE, UPDATE
- DCL의 종류 : GRANT, REVOKE, COMMIT, ROLLBACK
48. DDL(Data Definition Language)
- 데이터베이스의 정의/변경/삭제에 사용되는 언어이다
- 논리적 데이터 구조와 물리적 데이터 구조로 정의할 수 있다
- 논리적 데이터 구조와 물리적 데이터 구조 간의 사상을 정의한다
- 번역한 결과가 데이터 사전에 저장된다
| CREATE TABLE 기본테이블 ({ 열이름 데이터_타입 [NOT NULL],[DEFAULT 값]} [PRIMARY KEY(열이름_리스트)] [UNIQUE(열이름_리스트,…)] [FOREIGN KEY(열이름_리스트)] REFERENCES 기본테이블[(기본키_열이름)] [ON DELETE 옵션] [ON UPDATE 옵션] [CHECK(조건식)]; |
|---|
| - { }는 중복 가능한 부분, []는 생략 가능한 부분이다 - NOT NULL 은 특정 열에 대해 널(Null) 값을 허용하지 않을 때 기술한다 - PRIMARY KEY 는 기본키를 구성하는 속성을 지정할 때 기술한다 - FOREIGN KEY 는 외래키로 어떤 릴레이션의 기본키를 참조하는지를 기술한다 |
CASCADE vs RESTRICT
-
DROP View : View_이름 [CASCADE RESTRICT]; - CASCADE : 삭제할 요소가 다른 개체에서 참조 중이라도 삭제가 수행된다
- RESTRICT : 삭제할 요소가 다른 객체에서 참조 중일 경우 삭제가 취소된다
DDL 종류
- CREATE : 스키마, 도메인, 테이블, 뷰 정의
- ALTER : 테이블 정의 변경
- DROP : 스키마,도메인,테이블,뷰 삭제
49. DML(Data Manipulation Language)
- SELECT : 튜플을 검색할 때 사용한다
- INSERT : 튜플을 삽입할 때 사용한다
- DELETE : 튜플을 삭제할 때 사용한다
- UPDATE : 튜플의 내용을 변경할 때 사용한다
| SELECT 문 기본 구조 |
|---|
| SELECT 속성명 [ALL I DISTINCT] FROM 릴레이션명 WHERE 조건; [GROUP BY 속성명1, 속성명2,…] [HAVING 조건] [ORDER BYU 속성명[ASC I DESC]]; |
| - ALL : 모든 튜플을 검색(생략 가능) - DISTINCT : 중복된 튜플 생략 - ORDER BY 를 사용하며 내림차순은 DESC 르ㅜㄹ 사용한다. 오름차순의 경우 생략이나 ASC 를 사용한다 |
50. DCL(Data Control Language)
- COMMIT : 명령어로 수행된 결과를 실제 물리적 디스크로 저장하고, 명령어로 수행을 성공적으로 완료하였음을 선언한다
- ROLLBACK : 명령어로 수행에 실패하였음을 알리고, 수행된 결과를 원상 복귀시킨다
- GRANT : 데이터베이스 사용자에게 사용 권한을 부여한다
- REVOKE : 데이터베이스 사용자로부터 사용 권한을 취소한다
| GRANT : 권한 설정 |
|---|
| - GRANT 권한 ON 데이터 객체 TO 사용자 [WITH GRANT OPTION]; - WITH GRANT OPTION : 사용자가 부여받은 권한을 다른 사용자에게 다시 부여할 수 있는 권한을 부여한다 - 부여할 수 있는 권한 : UPDATE, DELETE, INSERT, SELECT |
| REVOKE : 권한 해제 |
| - REVOKE [GRANT OPTION FOR]권한 ON 데이터 객체 FROM 사용자 [CASCADE]; - GRANT OPTION FOR : 다른 사용자에게 권한을 부여할 수 있는 권한을 취소한다 - CASCADE : 권한을 부여받았던 사용자가 다른 사용자에게 부여한 권한도 연쇄 취소한다 - 부여할 수 있는 권한 : UPDATE, DELETE, INSERT, SELECT |
51. 하위 질의, SQL 연산자
하위 질의의 개념
- 하위 질의문은 하위 질의를 먼저 처리하고 검색된 결과는 상위 질의에 적용되어 검색된다
논리 연산자 설정
- AND : 이면서, 그리고 조건
- OR : 이거나, 또는 조건
- NOT : 부정 조건
BETWEEN ~ AND
- 구간 값 조건식이다
- BETWEEN 90 AND 95은 90 이상에서 95 이하까지의 범위를 의미한다
- WHERE 점수 >= 90 AND 점수 <= 95로 표현할 수 있다
52. 트랜잭션
트랜잭션의 특징
- 원자성(Atomicity) : 완전하게 수행 완료되지 않으면 전혀 수행되지 않아야 한다
- 일관성(Consistency) : 시스템의 고정 요소는 트랜잭션 수행 전후에 같아야 한다
- 격리성(Isolation, 고립성) : 트랜잭션 실행 시 다른 트랜잭션의 간섭을 받지 않아야 한다
- 영속성(Durability, 지속성) : 트랜잭션의 완료 결과가 데이터 베이스에 영구히 기억된다
트랜잭션 상태
- 활동(Active) : 초기 상태로 트랜잭션이 Begin_Trans 에서 부터 실행을 시작하였거나 실행 중인 상태이다
- 부분 완료(Partially Committed) : 트랜잭션의 마지막 연산이 실행된 직후의 상태로, 모든 연산의 처리는 끝났지만 트랜잭션이 수행한 최종 결과를 데이터베이스에 반영하지 않은 상태이다
- 완료(Committed) : 트랜잭션이 실행을 성공적으로 완료 연산을 수행한 상태이다
53. 뷰(View) 특징
- 뷰의 생성 시 CREATE 문, 검색 시 SELECT 문을 사용한다
- 뷰의 정의 변경 시 ALTER 문을 사용할 수 없고 DROP 문을 이용한다
- 뷰를 이용한 또 다른 뷰의 생성이 가능하다
- 하나의 뷰 제거 시 그 뷰를 기초로 정의된 다른 뷰도 함께 삭제된다
- 뷰에 대한 조작에서 삽입, 갱신, 삭제 연산은 제약이 따른다
- 뷰가 정의된 기본 테이블이 제거되면 뷰도 자동적으로 제거된다
댓글 남기기